
資料處理的常見狀況
列舉出 10 個最常碰到的狀況,而這些狀況又如何迅速用 pandas 解決
- 如何將資料轉置? (例如:把 column 變成 index 、或者整理成 panel data)
- 如何合併資料? (類似 Excel 中的 VLOOKUP)
- 如何操作多重索引值? (multi-index)
- 如何多重排序資料? (例如:先依日期排序、再依編號)
- 如何多重條件過濾資料? (例如:找出今天上漲的金融類股)
- 如何尋找和處理缺失值? (NA)
- 如何去除重複的資料?
- 如何處理時間格式? (年、月、日、日內)
- 如何改變資料頻率? (例如:從 5 秒變成 1 分鐘的頻率)
- 如何將資料分類後計算? (例如:計算特定產業近一天的報酬率)
繼上一篇用 pandas 解決 10 個資料處理問題 - (1) 介紹完如何處理前五個問題後,本篇介紹後五個。
以上每個問題用的範例都是獨立的,不一定要從頭看,可以看有沒有遇到類似的問題取用閱讀。
如何尋找和處理缺失值? (N/A)
缺失值確實是個很頭大的問題,常常在計算時因為缺失值而失敗,但又無法輕易找到缺失值在哪。
舉例來說,今天我們有個股價的表格

表面看起來一片祥和,可是圖一畫出來才發現少了段資料
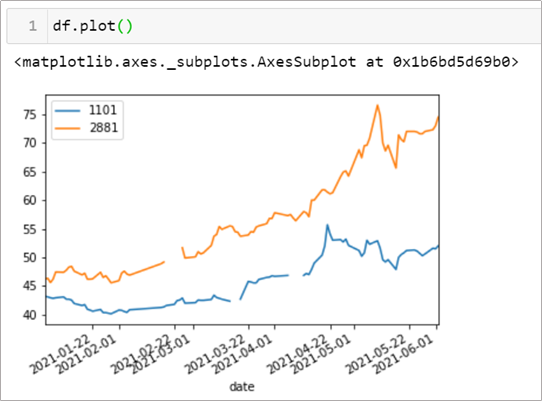
此時我們只能透過日期軸的訊息大致推斷各個欄位的缺失值所在位置,但沒有辦法立刻的抓出來確切在哪,這時該如何處理?
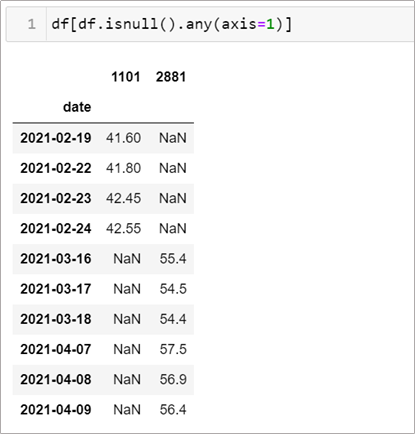
情境6–1: 如何尋找缺失值?
經過了許多資料處理的經驗後,我覺得最快的寫法是這樣。其中的 axis 參數就如同許多function的用法一樣,如果為1就是列出有缺失的column,0則是印出row。
df[df.isnull().any(axis=1)]
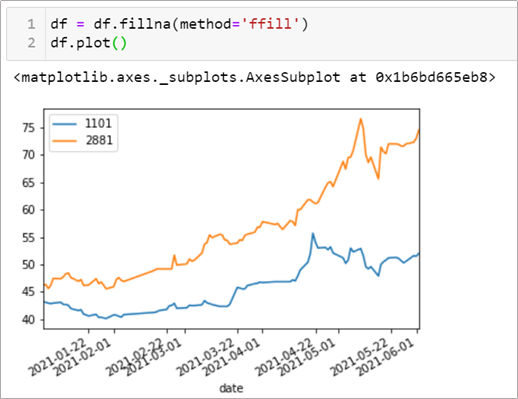
情境6–2: 缺失值要怎麼處理?
有三種最常見
- 直接捨棄
- 補0
- 補前值
分別可以這樣寫,我們用補前值來處理
df.dropna() # 直接捨棄
df.fillna(0) # 補零
df.fillna(method='ffill') # 補前值
如何去除重複的資料?
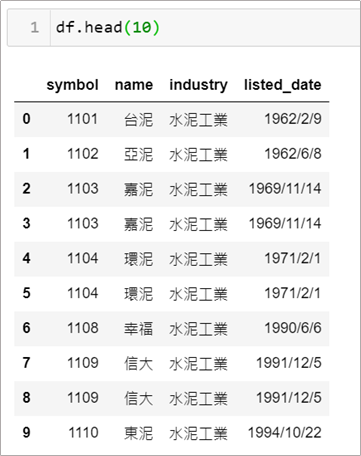
假設現在有個表格如下,我們拿到了個不乾淨的資料,有重複的資訊出現,像第2列和第3列的資料其實只需要一筆而已
情境7–1: 如何迅速去除重複的資料?
經過試過了許多方法,發現這個最快,先用 df.duplicated() 找出有重複的列,再加上 ~ 取出非重複的部份。
df[~df.duplicated()]

如何處理時間格式? (年、月、日、日內)
時間序列相關的資料在時間格式處理的次數會相當頻繁,在python中都是以 datetime 套件來處理時間物件。
通常在讀取資料時,用 pd.read_csv ,再加入參數 parse_dates=['col1'] ,如此一來 col1 在讀取後會變為時間格式。
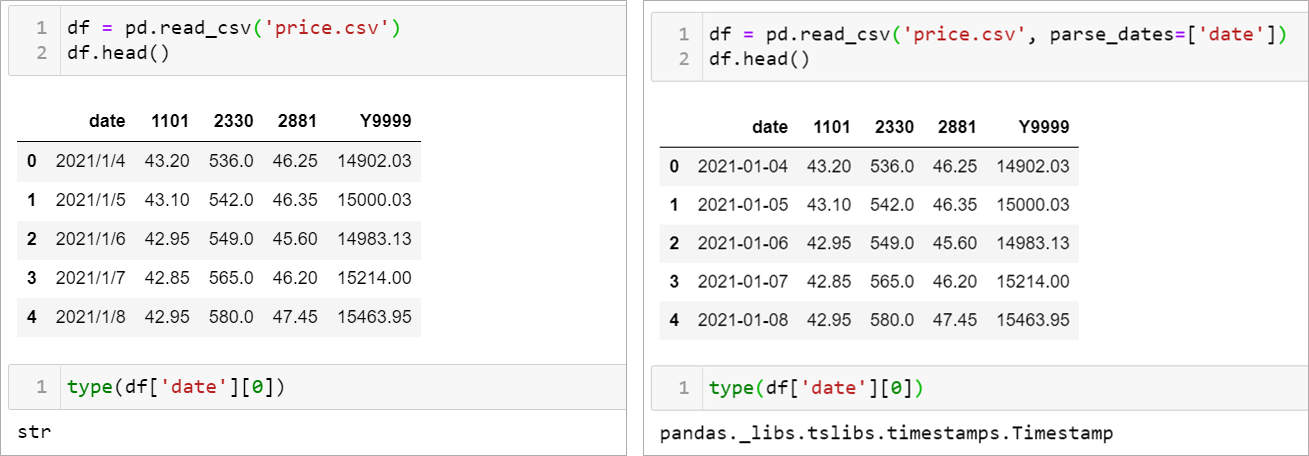
又或者可以透過 pd.to_datetime(df['col1'])來處理。

情境8–1: 要如何篩選出 2 月資料呢?
特別的地方在於要先寫 dt ,再寫年、月、日的屬性

情境8–2: 要如何篩選出每個月 5 號的資料呢?
和8–1雷同,只是換成了 day ,同理而言,要用年份篩選就換成 year。

講完低頻率資料後,接著介紹日內的資料處理。
通常我們拿到了日內資料會像這樣,通常日內資料的時間都是日期加上時間的格式。下圖為選擇權的日內資料
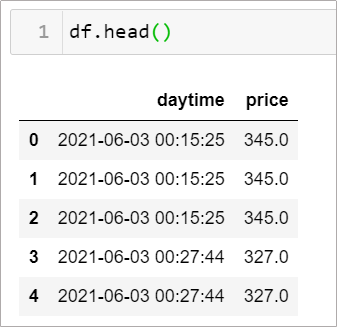
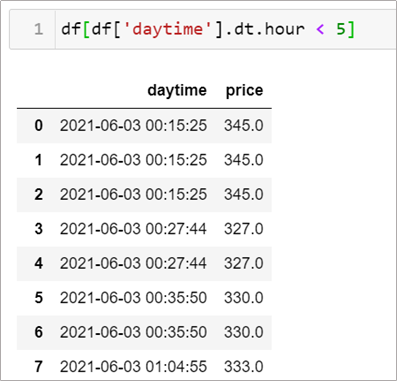
情境8-3: 如何選取當天夜盤(半夜 12 點到早上 5 點)的成交行情?
處理日內也是同理,只是頻率又更高,例如我選擇 hour 小於5。
至於更細的時間則可以搭配第5題多重條件篩選完成。
df[df['daytime'].dt.hour < 5]
如何改變資料頻率?
不管是高頻低頻的資料都會有變換頻率的需要,例如有日報酬率,可能會轉為觀察月報酬,或是日內5秒的資料,轉換成1分鐘的頻率。
假設我們有筆日內資料如下
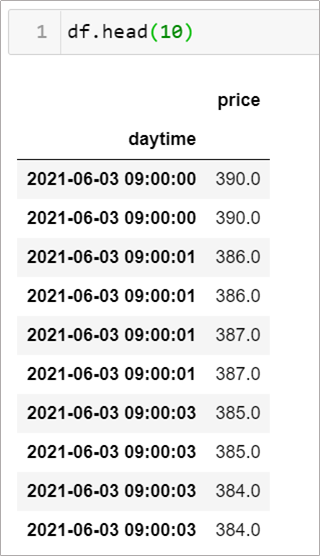
情境9-1: 要如何把資料頻率改為 15 秒或是 1 分鐘?
其實方法都一樣,一個函數就完成了。特別的地方在於最後我用了 last() ,也就是該區間的最後一個值,還有許多常用的像是
first()區間第一值max()區間最大值min()區間最小值mean()區間平均std()區間標準差 …
像取每15秒的最後一筆值,就可以寫成
df.resample('15S').last()
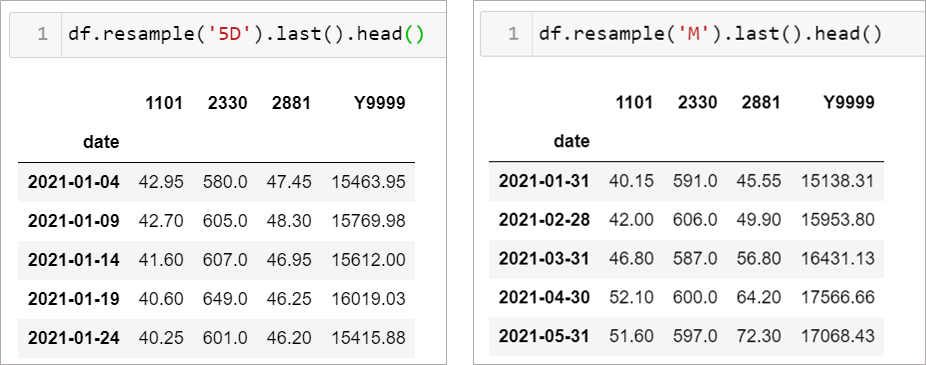
情境9–2: 那日頻率的資料如何處理呢?
其實大同小異,假設有個資料如下

試著改成5天頻率和每月的資料,同樣OK。
如何將資料分類後計算?
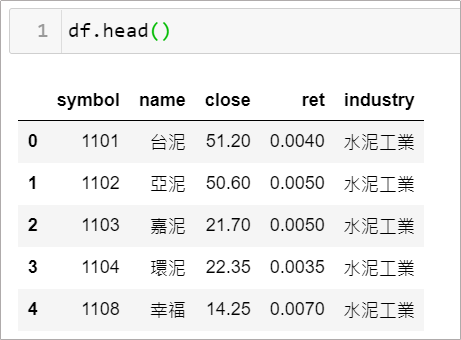
假如現在有一表格如下,是某天上市公司股票的收盤價和報酬率
情境10–1: 如何計算當天各產業(industry)股票的平均報酬率呢?
類似的分類問題常遇到,其實可以用 groupby解決,先挑出來報酬率和產業欄位後,再以產業分類,並取平均。
後面的 mean() 同樣可以換成其它計算方式,如情境9–1所述。
df[['industry', 'ret']].groupby('industry').mean()

結語
以上為資料處理常見問題,涵蓋了大部份處理時間序列資料的議題,這些技巧彼此間互相搭配使用,運用熟練,在處理資料上一定能更有效率!