
為何需要資料處理?
在進行研究工作時,會將資料套用到模型上,觀察要探討的議題,而通常拿到的資料都有些殘缺、或是資料類型的問題,此時就要做資料處理的工作。
在執行研究前進行資料預處理的過程往往是最麻煩的,資料處理久了後,其實會發現遇到的問題大同小異,今天就列舉出 10 個最常碰到的狀況,而這些狀況又如何迅速用 pandas 解決
- 如何將資料轉置? (例如:把 column 變成 index 、或者整理成 panel data)
- 如何合併資料? (類似 Excel 中的 VLOOKUP)
- 如何操作多重索引值? (multi-index)
- 如何多重排序資料? (例如:先依日期排序、再依編號)
- 如何多重條件過濾資料? (例如:找出今天上漲的金融類股)
- 如何尋找和處理缺失值? (NA)
- 如何去除重複的資料?
- 如何處理時間格式? (年、月、日、日內)
- 如何改變資料頻率? (例如:從 5 秒變成 1 分鐘的頻率)
- 如何將資料分類後計算? (例如:計算特定產業近一天的報酬率)
以上每個問題用的範例都是獨立的,不一定要從頭看,可以看有沒有遇到類似的問題,本篇介紹前五個常見問題的處理方式。
如何將資料轉置?
假設我們有下圖這樣的股價資料

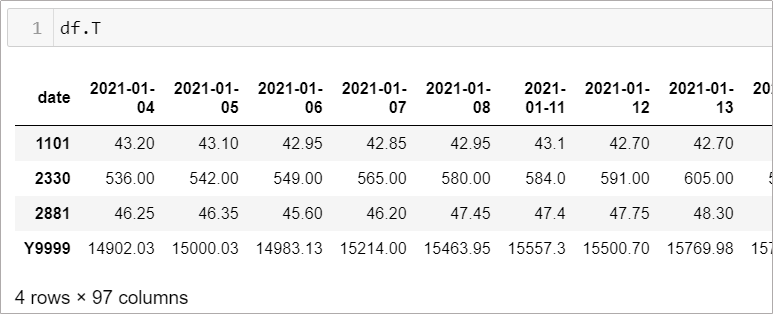
情境1–1: 將 column 和 index 轉換怎麼做?
df.T
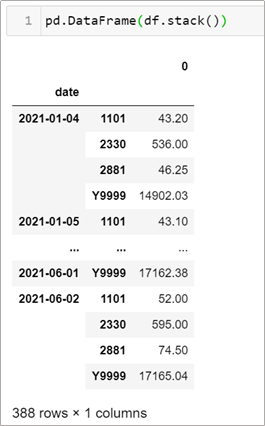
情境1–2: 要將資料變成 panel data 的形式怎麼做?(做迴歸分析時常用到)
先用 df.stack(),再用 pd.DataFrame() 包起來。
pd.DataFrame(df.stack())
如何合併資料?
第二題每個情境會有多個資料,首先假設我們有下圖這樣兩個表格,分別為兩檔股票的股價資料
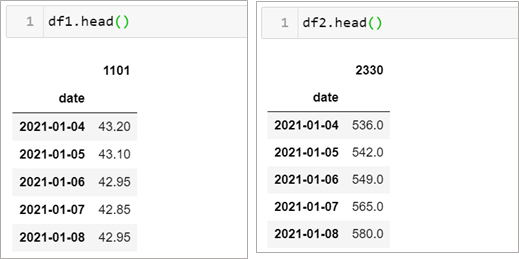
情境2–1: 如何將資料左右合併呢?
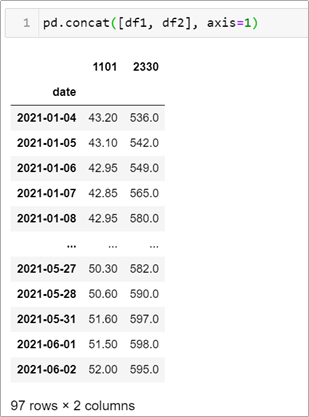
使用 pd.concat() ,設定 axis 設定1代表左右合併(欄位合併, column bind),預設為0代表(列合併, row bind)
pd.concat([df1, df2], axis=1)
情境2–2: 如何完成查表、對照的功能呢?(Excel 中的 VLOOKUP)
假設現在我們有兩個表格資料,分別為股票的公司資訊,和價格資訊,本次要將公司資訊加到右邊價格資訊的表格
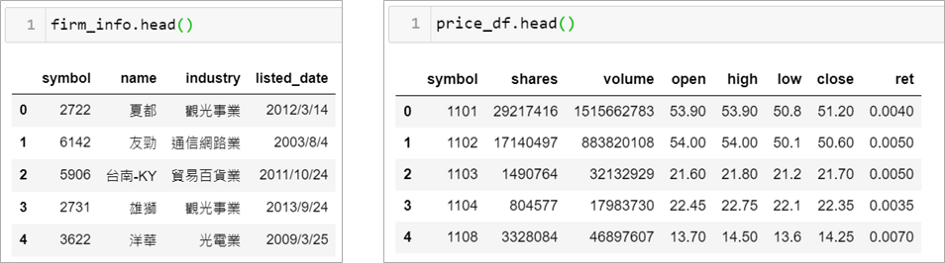
在資料順序不同的情況下,就不能像情境2–1直接合併解決,要合併就需要有查找的功能,讓正確的資料相互對應。
透過 pd.merge() 來解決, on 表示兩個表格對應的欄位名稱,例子中兩個表格都有 symbol ,以這個欄位為準合併兩個表格
pd.merge(price_df, firm_info, on='symbol')

如何操作多重索引值?(multi-index)
假如現在有一資料如下,有多重的索引值,也就是有一層以上的index,此時開如何處理呢?
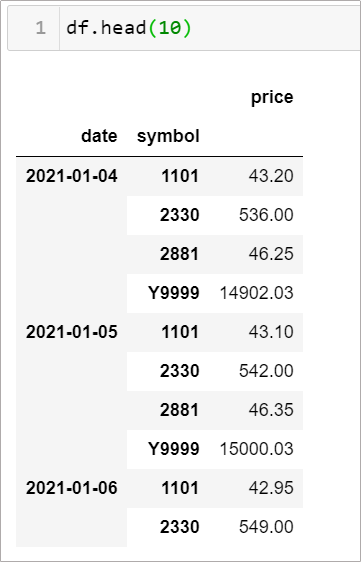
情境3-1: 我只想留下其中一欄作為索引(date 或 symbol),該怎麼做?
使用 df.reset_index(0) ,將第一個欄位(最外層),也就是date,推回到表格中成為一個欄位,用 1 則是推回第二個,以此類推
df.reset_index()
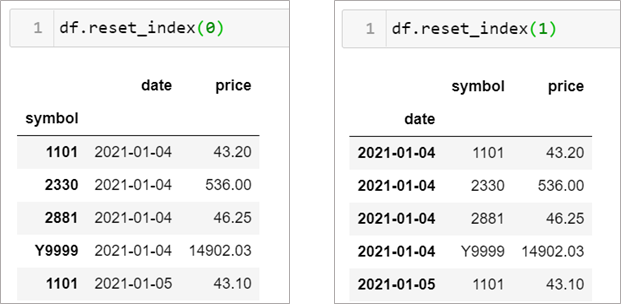
當然,如果沒給數字的話就是全部。
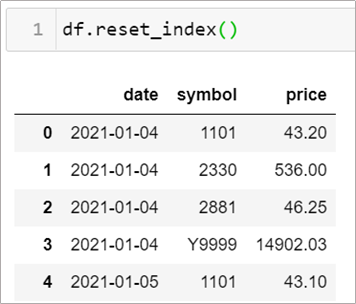
情境3–2: 那要如何選取索引的值呢?
普通我們都會透過 df.index 的值來選取索引的值,multi-index當然也適用,不過要選取multi-index的其中一個index的話,則可以這樣寫
df.index.get_level_values()
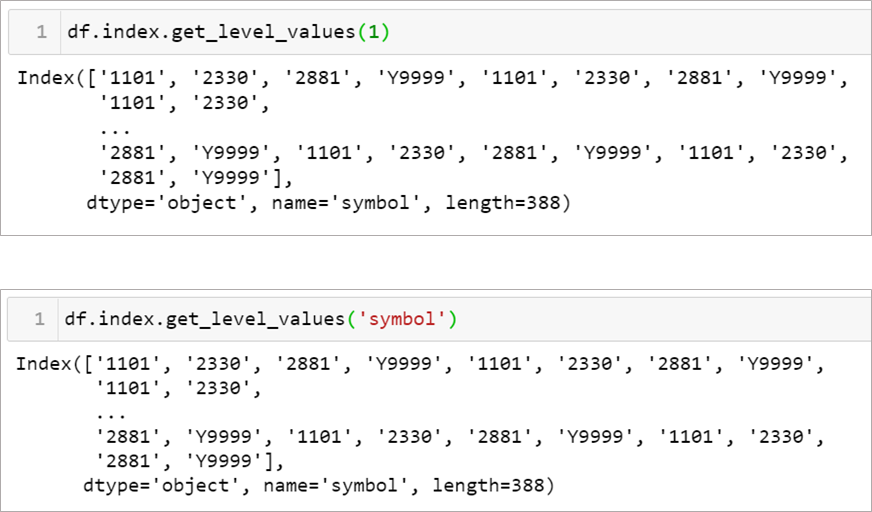
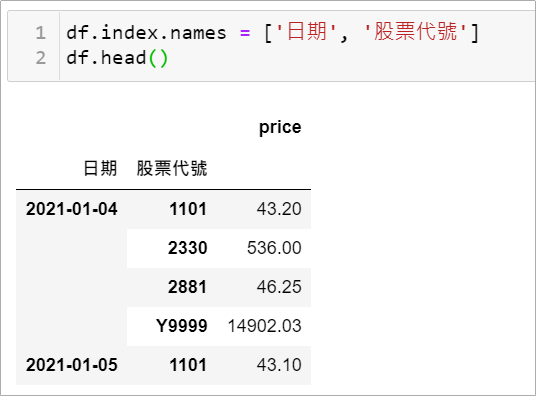
不管是用順序或索引欄位名稱都可以指定選取。而多重索引欄位名稱可以這樣更改
df.index.names = [‘name1’, ‘name2’]
如何多重排序資料?
假設現在有筆資料如下,欄位分別為日期、股票代號、股票價格,看的出來資料順序是被打亂的
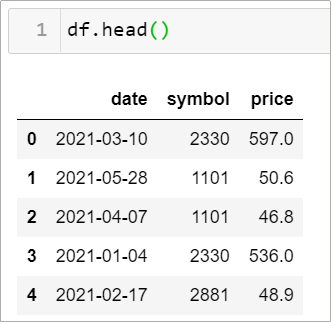
情境4–1: 要如何先依日期,再依股票代號排序呢?
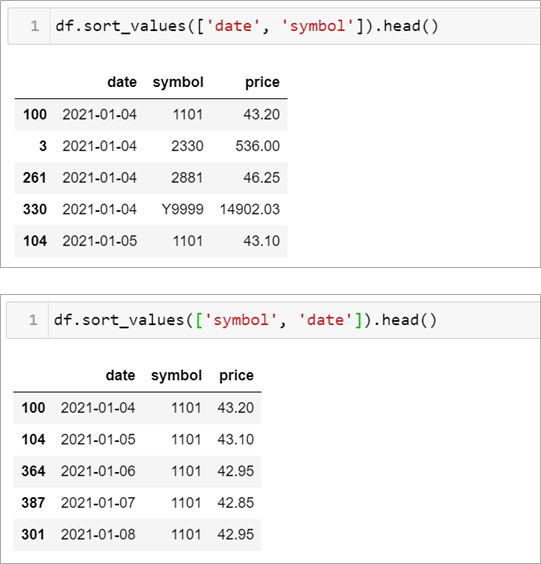
可以透過 df.sort_values(['col1', 'col2']) 來進行條件排序,而欄位名稱的順序也代表排序的優先順序,可以看下面的例子
第二張圖中先放 symbol ,就變成先以 symbol 優先排序。
如何多重條件過濾資料?
假設現在有筆資料如下,個別股票的基本資料,像產業、收盤價…等
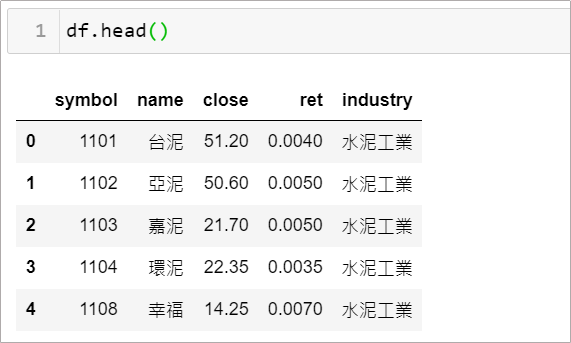
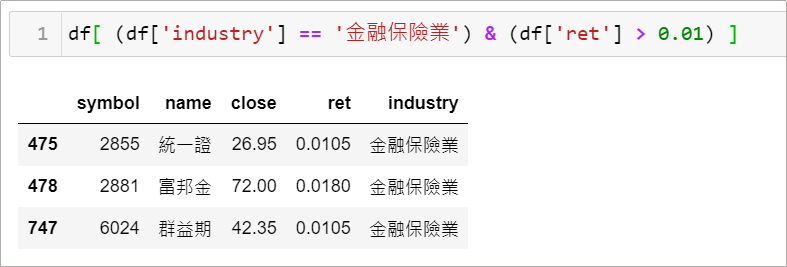
情境5–1: 我想找出當天金融保險類股、漲幅超過 1% 的股票
簡易的透過多條件選取完成,但須注意的是在多條件篩選時,每個條件前後要用 () 包起來,中間用 & 做間隔
df[ (df[‘industry’] == ‘金融保險業’) & (df[‘ret’] > 0.01) ]
結語
以上就是 5 個常見的資料處理狀況及技巧,下一篇用 pandas 解決 10 個資料處理問題 - (2)介紹另外 5 個。