
selenium是什麼?
selenium原先是Python網頁自動化測試的套件,但因為能模仿使用者操作的行為,近來演變成爬蟲的最後一把武器。
為什麼會說是最後一把呢? 因為在爬蟲時的選項大多仍以requests搭配BeautifulSoup再加上Chorme解決
Selenium雖然強大,能夠使用瀏覽器的仿真操作,但相對就必須耗費比較多的資源。
不過這麼好用的套件怎麼能不認識他,本文將列出Selenium的常用功能。
瀏覽器(Webdriver)
如同前面提到的仿真操作,使用Selenium時需要有瀏覽器來進行,目前Selenium支援了許多瀏覽器,主流的都有包含在內,更詳細的可參考Official Document
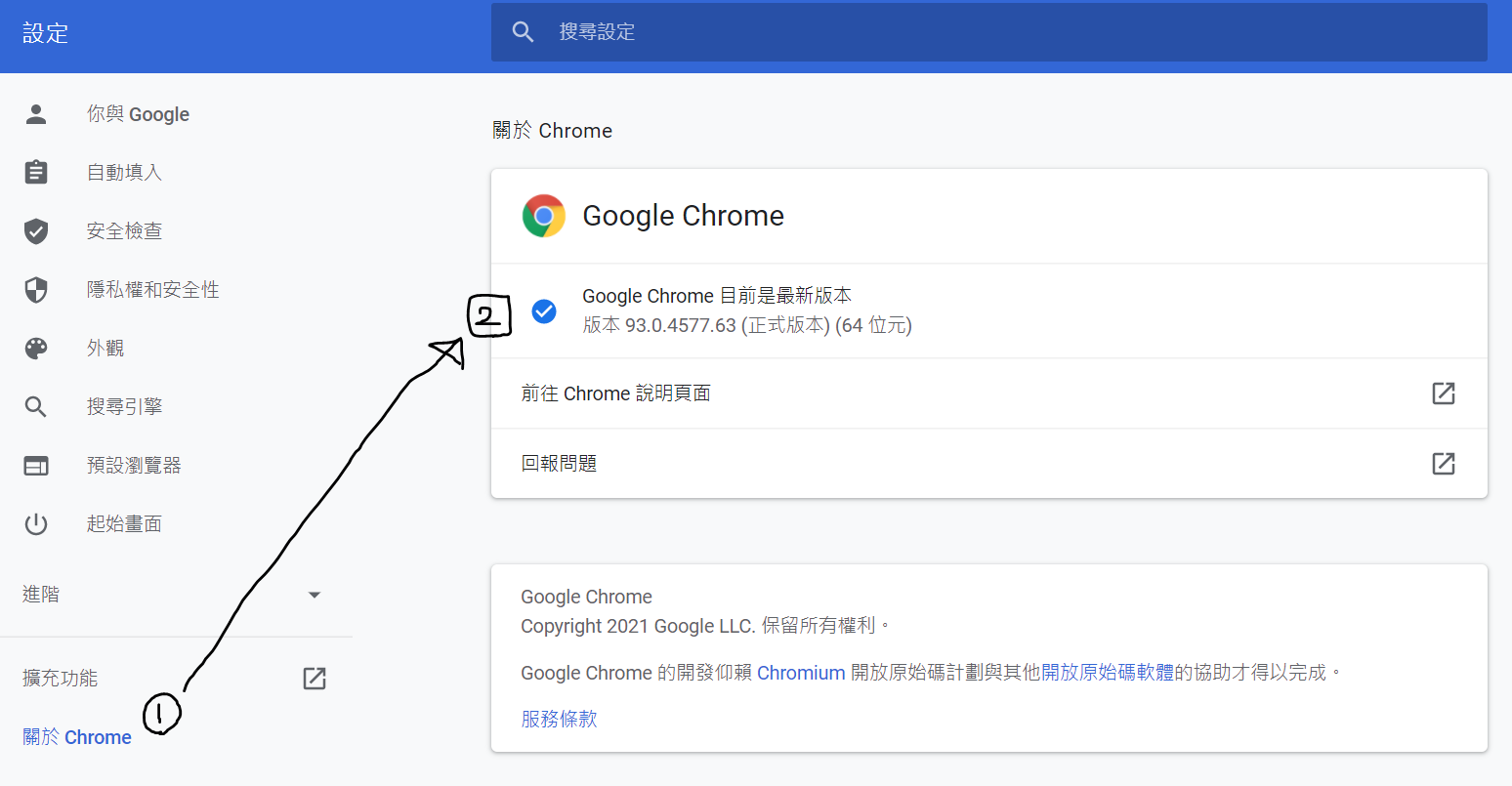
以Chrome為例,下載時會出現多個版本號可選擇

能透過Chorme右上角的選項 > 設定 > 關於Chorme,找到目前使用Chrome的版本號,下載對應的號碼版本即可
常用功能
下載瀏覽器後,放在專案資料夾,或是任何找的到的地方。
driver.get(url)等於瀏覽網頁,以下方的例子,執行後將瀏覽器將會轉向google.com
from selenium import webdriver
main_url = 'https://google.com'
chromedriver = 'chromedriver.exe'
driver = webdriver.Chrome(chromedriver)
driver.get(main_url)
指定單一物件(find element)
在網站中的<tag>可能有許多的attributes,下面有幾種Method能夠使用,透過指定id、name、class name等幾種見的屬性來指定
driver.find_element_by_id
driver.find_element_by_name
driver.find_element_by_xpath
driver.find_element_by_link_text
driver.find_element_by_partial_link_text
driver.find_element_by_tag_name
driver.find_element_by_class_name
driver.find_element_by_css_selector
指定多個物件(find elements)
如果要一次指定多個物件,只要把Method中的element加上s即可
例如,要找尋多個name為post的標籤
driver.find_elements_by_name('post')
這結果將會回傳一個list物件
指定絕對位置xpath
find_element_by_xpath需要被特別介紹,因為應用的頻率很高。如果想要指定一個name為main的<p>,恰巧同個網頁上也有其他標籤name為main。
這時就可以使用xpath進行定位,下面的範例就能精確地抓出name為main的<p>
driver.find_element_by_xpath("//p[@name='main']")
包含特定文字的物件(contain)
如果不幸的,想找的標籤並沒有attributes,這時也能透過文字進行指定。
假設要指定找尋所有包含的下載文字的td標籤
ele = driver.find_elements_by_xpath("//td[contains(text(), '下載')]")
登入(Login)-輸入帳號密碼
在爬蟲時,也常遇到需要登入的場景,Selenium也用簡單三步驟完成登入這件事。
先指定帳號密碼的標籤(find)
username = driver.find_element_by_name('username')
password = driver.find_element_by_name('password')
輸入帳號密碼(send_keys)
username.send_keys("your username")
password.send_keys("your password")
點擊登入(Click)
login_btn = driver.find_element_by_name('login')
login_btn.click()
開新分頁(New Tab)、切換分頁(Switch)
爬蟲時也會遇到需要新開分頁的場景,原本的get只會在同一個分頁中不斷瀏覽新的網頁
如果要開新分頁該怎麼做呢?
先執行並進入第一個網頁
from selenium import webdriver
main_url = 'https://google.com'
tab_url = 'https://www.facebook.com'
chromedriver = 'chromedriver.exe'
driver = webdriver.Chrome(chromedriver)
driver.get(main_url)
接著執行這行開啟新分頁
driver.execute_script("window.open('');")
再執行這行切換到新開的分頁,並選擇新分頁要瀏覽的網頁
driver.switch_to.window(driver.window_handles[1])
driver.get(tab_url)
瀏覽器選項(Options)
在使用Selenium爬蟲時,也有許多客製化選項能夠調整
隱藏瀏覽器(headerless)
原先執行爬蟲時,瀏覽器會出現在畫面上運行,但其實是可以隱藏的。
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
options = Options()
options.add_argument('--headless')
chromedriver = 'chromedriver.exe'
driver = webdriver.Chrome(chromedriver , chrome_options=options)
driver.get(main_url)
隱藏瀏覽器的log資訊
options.add_argument("--log-level=OFF")
參考連結
Selenium with Python - Selenium Python Bindings 2 documentation