
五因子模型(Fama-French five-factor asset pricing model)
因子模型在財務金融世界中算相當熱門的議題,許多人都希望找出能解釋報酬率的因子,想探詢股價報酬率究竟受到甚麼變數影響? 而Fama-French因子模型最廣為使用,其知名度和引用數量之高很值得好好學習。
今天介紹的五因子由最起初的單因子模型開始演進,單因子模型也就是大家耳熟能詳的資本資產訂價模型(Capital Asset Pricing Model, CAPM) ,利用市場報酬率解釋了股票報酬率,接著加上Fama and French(1993)又提出市值和淨價市值比兩項因子,2015年兩位大師再提出了兩項因子,獲利能力和投資水平,共為以下五個因子(後來還有動能因子的加入,本篇僅提到五因子)
- 市場報酬率(Market Return)
- 市值(Small Minus Big, SMB)
- 帳面市值比(High Minus Low, HML)
- 獲利能力(Robust Minus Weak, RMW)
- 投資水平(Conservative Minus Aggressive, CMA)
這些因子彼此間關聯性低,對於股票報酬率的解釋能力強,也因此在財務金融界一直享有盛名。
本篇文章將透過Python實作實作財務金融界著名的Fama-French因子模型,以臺灣上市公司股票作為樣本,資料期間為2012至2020年,資料為月頻率,共計108個月。
因子計算介紹
市場報酬率(Market Return) / 頻率:月
用大盤指數作為市場報酬率計算代表,以臺灣為例即為發行量加權股價指數,而本篇使用了包含股利在裏頭,不受除權息影響的發行量加權股價報酬指數,雖說是市場報酬率,但其實需要的是高於無風險利率(Risk-free rate)的部份,也因此在計算時都會將市場報酬再扣掉無風險利率。
市值因子(Market Value) / 頻率:月
參考的變數為公司市值,而區分公司屬於大型或小型的方式經蒐集資訊後發現有兩種,首先將公司依市值排序,兩種分類方法分別為
- 小於中位數者歸類為小公司,高於則歸類為大公司
- 市值為整體10%以下為小公司,90%以上為大公司
而在French的網站中表示新興市場的計算方式適用於第2種,因此本篇也使用第2種。
淨價市值比(Book-to-Market) / 頻率:年
參考的變數為淨價市值比(B/M) ,透過帳面股東權益(Equity)除於市值(Market Value),得到淨價市值比,接著再排序並以30%, 40%, 30%區分為成長(low/growth)、中(medium/netural)、大(high/Value)三種,接下來的獲利能力和投資因子也是以同樣門檻進行區分。
獲利能力(operating profitability) / 頻率:年
參考變數為營業利益除以股東權益,也有看到有人使用營業利益率解釋,本篇先以French所寫的計算方法為主(詳見文末參考連結),也就是從營業收入(Revenue)減去銷貨成本(Cost of goods sold)後再減去費用、利息支出…等後除以股東權益,並如同淨價市值比的拆分方法由低到高依序區分為貧弱(weak)、中等(Netural)、穩健(Robust)。
投資因子(Investment) / 頻率:年
參考變數為總資產(asset)的成長率,假設今年為2021年,則參考股票於2019會計年度結束至2020會計年度間總資產變化,並除於2019年底總資產,作為投資因子的指標,意即前一年總資產成長率。
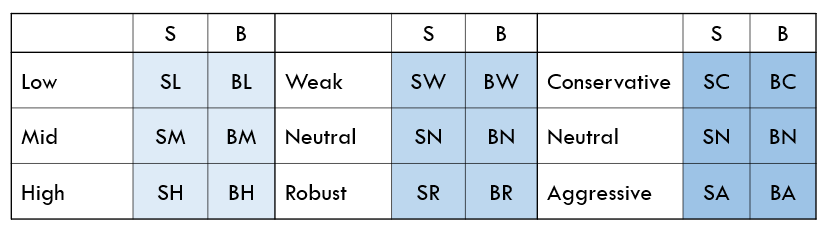
透過各個因子的變數,可以將股票分類3x2的矩陣,各因子都是以市值搭配其他三個變數,B/M、Operating Profitability、Investment,而矩陣中的英文代表符合分類條件的股票平均報酬率。
舉例來說,最左上角的SL即為當期市值低於整體10%以下且淨價市值比位於整體30%以下的公司 股票之平均報酬率,以此類推。
而SMB市值因子的計算先將市值搭配各類因子的結果計算出來,並觀察小公司和大公司間差的平均,再計算整體的平均,公式如下
$$ SMB_{bm}=\frac{(SL+SM+SH)-(BL+BM+BH)}{3} $$
$$ SMB_{op}=\frac{(SW+SN+SR)-(BW+BN+BR)}{3} $$
$$ SMB_{inv}=\frac{(SC+SN+SA)-(BC+BN+BA)}{3} $$
$$ SMB=\frac{SMB_{bm}+SMB_{op}+SMB_{inv}}{3} $$
另外HML、RMW、CMA的計算則簡單許多,也能從字面立刻理解
$$ HML=\frac{(SH+BH)-(SL+BL)}{2} $$
$$ RMW=\frac{(SR+BR)-(SW+BW)}{2} $$
$$ CMA=\frac{(SC+BC)-(SA+BA)}{2} $$
以上即為各個因子的數值的計算公式。
五因子模型估計過程
讀取資料
首先先將資料讀取進來,總共有四個檔案,分別為公司特徵(factor)、公司市值(market_value.csv)、股票月報酬率(ret.csv)、市場報酬率加無風險利率(rm_rf.csv)。
並且將市值及報酬率的欄位資料類型改為int,方便等等呼叫
import pandas as pd
factor_df = pd.read_csv('factors.csv')
market_value = pd.read_csv(
'market_value.csv', index_col='date', parse_dates=['date']
)
ret_df = pd.read_csv('ret.csv', index_col='date', parse_dates=['date'])
rm_rf = pd.read_csv('rm_rf.csv', index_col='date', parse_dates=['date'])
market_value.columns = market_value.columns.astype(int)
ret_df.columns = ret_df.columns.astype(int)
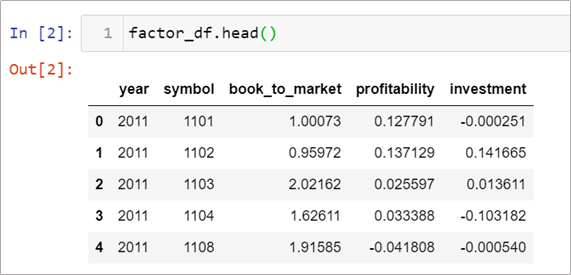
接著來看看各檔案中的欄位, factor_df中的欄位有年份(year)、股票代號(symbol)、淨價市值比(book_to_market)、獲利能力(profitability)、投資(investment),資料頻率為年
下方圖中book_to_market、profitability和investment即為前一節所介紹各個因子所使用的變數
再來看到 market_value和 ret_df欄位即為為各檔股票代號
最後的 rm_rf 則是臺灣銀行當期一個月期的無風險利率(rf)和報酬指數報酬率(rm)。
計算因子
我們先嘗試著計算一期的各項數據,接著再用迴圈計算整個資料期間(以下程式碼為了好理解,重複的部份會比較多,寫法hard coded)
先把各個月份包在一個list中,我們先嘗試計算第一個月份,2012的1月
year_month_list = list(ret_df.index)
current_ym = year_month_list[0]
current_month = current_ym
correspond_year = current_ym.year — 1
我們接著來篩選符合條件的股票代號,從 market_value 中,先篩選出目前計算的月份。
再用市值排序,選出小公司和大公司的股票代號,命名為 small 和 big
sorted_mv_symbols = market_value.loc[
current_ym
].sort_values().dropna().index
small_threshold = int(len(sorted_mv_symbols)*0.1)
big_threshold = int(len(sorted_mv_symbols)*0.9)
small = sorted_mv_symbols[0:small_threshold]
big = sorted_mv_symbols[big_threshold:]
區分出大小公司後,接著利用前一年的資料(2011)的公司特徵進行分類,分別依照前一節介紹的門檻,排序後得出
book-to-market 區分為 low 、 mid 、 high
profitability 區分為 weak 、 neutral_pr 、 robust
investment 區分為 conservative 、 neutral_inv 、 aggressive
# book-to-market
sorted_by_bm_symbols = list(factor_df[
factor_df['year'] == correspond_year
].sort_values('book_to_market')['symbol'])
total_len = len(sorted_by_bm_symbols)
threshold1, threshold2 = (int(total_len*0.3), int(total_len*0.7))
low = sorted_by_bm_symbols[0:threshold1]
mid = sorted_by_bm_symbols[threshold1:threshold2]
high = sorted_by_bm_symbols[threshold2:]
# profitability
sorted_by_op_symbols = list(factor_df[
factor_df['year'] == correspond_year
].sort_values('profitability')['symbol'])
total_len = len(sorted_by_op_symbols)
threshold1, threshold2 = (int(total_len*0.3), int(total_len*0.7))
weak = sorted_by_op_symbols[0:threshold1]
neutral_pr = sorted_by_op_symbols[threshold1:threshold2]
robust = sorted_by_op_symbols[threshold2:]
# investing
sorted_by_inv_symbols = list(factor_df[
factor_df['year'] == correspond_year
].sort_values('investment')['symbol'])
total_len = len(sorted_by_inv_symbols)
threshold1, threshold2 = (int(total_len*0.3), int(total_len*0.7))
conservative = sorted_by_inv_symbols[0:threshold1]
neutral_inv = sorted_by_inv_symbols[threshold1:threshold2]
aggressive = sorted_by_inv_symbols[threshold2:]
接著把各個篩選結果的股票代號裝在 factor_result 這個 dict 中
factors_result = {
'low': low,
'mid': mid,
'high': high,
'weak': weak,
'neutral_pr': neutral_pr,
'robust': robust,
'conservative': conservative,
'neutral_inv': neutral_inv,
'aggressive': aggressive,
}
然後取出符合條件的市值和因子的股票代號,取交集後計算這些股票當月的平均報酬率,接著存在 factors_ret 中。
factors_ret = {}
for level in factors_result.keys():
s_qualified_symbol = set(small) & set(factors_result[level])
ret = ret_df[s_qualified_symbol].loc[current_month].mean()
factors_ret[('small', level)] = ret
b_qualified_symbol = set(big) & set(factors_result[level])
ret = ret_df[b_qualified_symbol].loc[current_month].mean()
factors_ret[('big', level)] = ret
執行到這,factors_ret 裡頭會是這樣,裝載著前一節3x2的矩陣中各個條件下的股票平均報酬率。
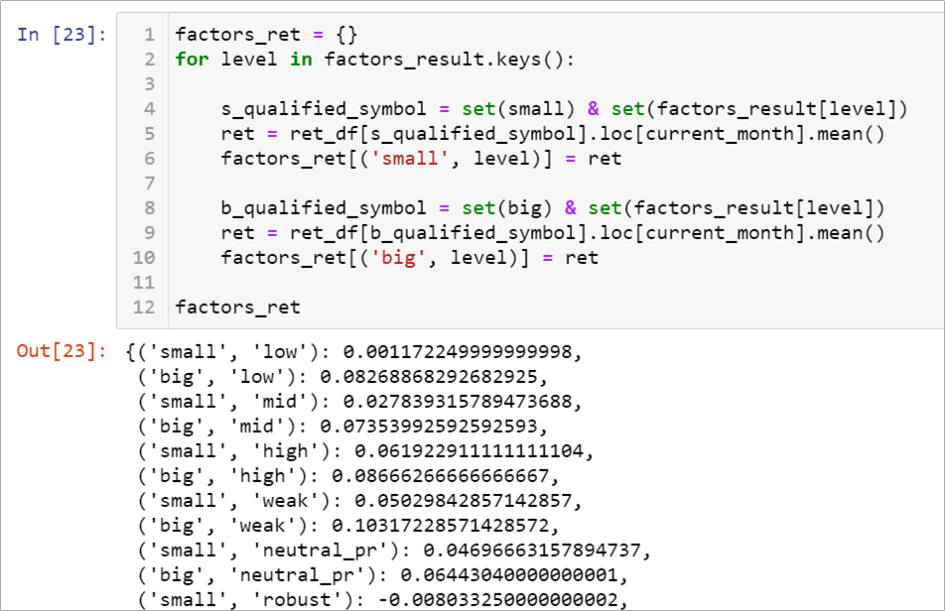
接著再用上一節的計算公式,利用 factors_ret 中的各個報酬率計算因子,以及用市場報酬率減無風險利率得出 Rm_Rf 。
small_ret = 0
big_ret = 0
for ret in factors_ret.keys():
if ret[0] == 'small':
small_ret += factors_ret[ret]
if ret[0] == 'big':
big_ret += factors_ret[ret]
SMB = (small_ret — big_ret) / 9
low_ret = 0
high_ret = 0
for ret in factors_ret.keys():
if ret[1] == 'low':
low_ret += factors_ret[ret]
if ret[1] == 'high':
high_ret += factors_ret[ret]
HML = (high_ret — low_ret) / 9
weak_ret = 0
robust_ret = 0
for ret in factors_ret.keys():
if ret[1] == 'weak':
weak_ret += factors_ret[ret]
if ret[1] == 'robust':
robust_ret += factors_ret[ret]
RMW = (robust_ret — weak_ret) / 9
aggr_ret = 0
cons_ret = 0
for ret in factors_ret.keys():
if ret[1] == 'aggressive':
aggr_ret += factors_ret[ret]
if ret[1] == 'conservative':
cons_ret += factors_ret[ret]
CMA = (cons_ret — aggr_ret) / 9
rmrf_data = rm_rf.loc[current_month]
Rm_Rf = rmrf_data.rm — rmrf_data.rf
執行到這後,將可以計算出2012年1月各個公司特徵因子的數值。
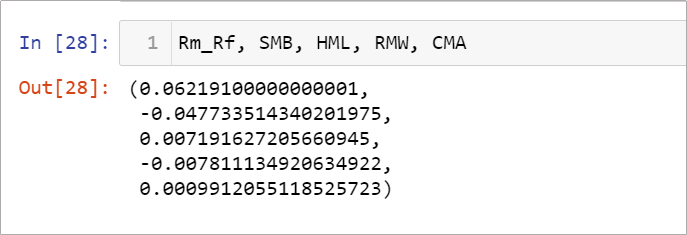
完成了一個月的計算,接著就是用迴圈完成整個資料期間的計算,如此一來,就能夠得出臺灣上市公司市場各因子逐月數值,用於建構因子模型,詳細可以看最下面完整程式碼的內容。
因子相關係數
各個因子間的相關係數如下
factor_data.corr()
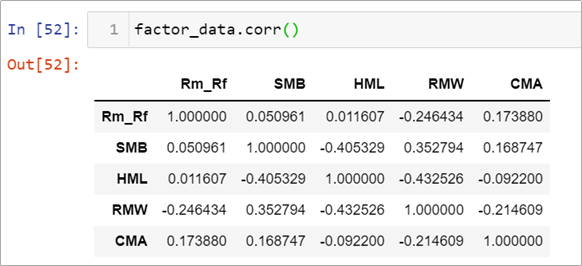
各因子間彼此相關係數不高,越接近0可避免共線性問題。
估計結果
在最後也用各個因子和股票報酬率進行迴歸分析,使用整個資料期間完全無缺失值的公司,共739間,其中有顯著正alpha的僅53間、而顯著負alpha的有2間,其餘683間不顯著,五因子模型在解釋臺灣上市公司股票報酬率的表現上算還不錯。
參考連結
Kenneth R. French - Description of Fama/French Factors