
為何需要Python財務報表爬蟲?
在做股票投資分析時,有人習慣用基本面分析,也有人喜歡看技術線圖,而基本面分析往往會用到公司財務報表的資料,而目前有將財務報表資訊做整理的網站並不多。
因此如果能靠簡單的幾行程式爬取財務報表,而不用每次都經過繁瑣的程序去下載,將能省下更多時間專注在研究上。
財務報表爬蟲實作
財務報表在公開資訊觀測站上都能夠自行下載,如果我們僅需要一季的資料,那確實不用寫程式,靠手動滑鼠點點就可以了,但如果同時要下載2年份的,這時麻煩就來了
1.確認爬取目標
爬蟲儘管聽起來是個很高大上的詞,白話就是網路擷取,Python簡單好學的特性已經大幅降低了爬蟲的學習門檻。
而要爬蟲第一步就是確認爬取目標,今天我們以台積電的綜合損益表作為抓取目標。
我們先進到公開資訊觀測站,依序點選「財務報表」→「採IFRSs後」→「合併/個別報表」→「綜合損益表」,接著我們選擇歷史資料,年度109,季別1,當按下查詢後下面立刻出現了我們要找的資料,並確認這是我們要爬取的目標

2.設計爬取方法
在確認爬取目標後,接著要想辦法把資料抓下來,而如同我們在爬取股價的教學文中所說的,我們先嘗試著把資料爬下來一遍,接著再用迴圈完成爬取所有想要的資料。
先回到公開資訊觀測站的網頁(請使用Chrome)並按下F12,這時會出現一個視窗。
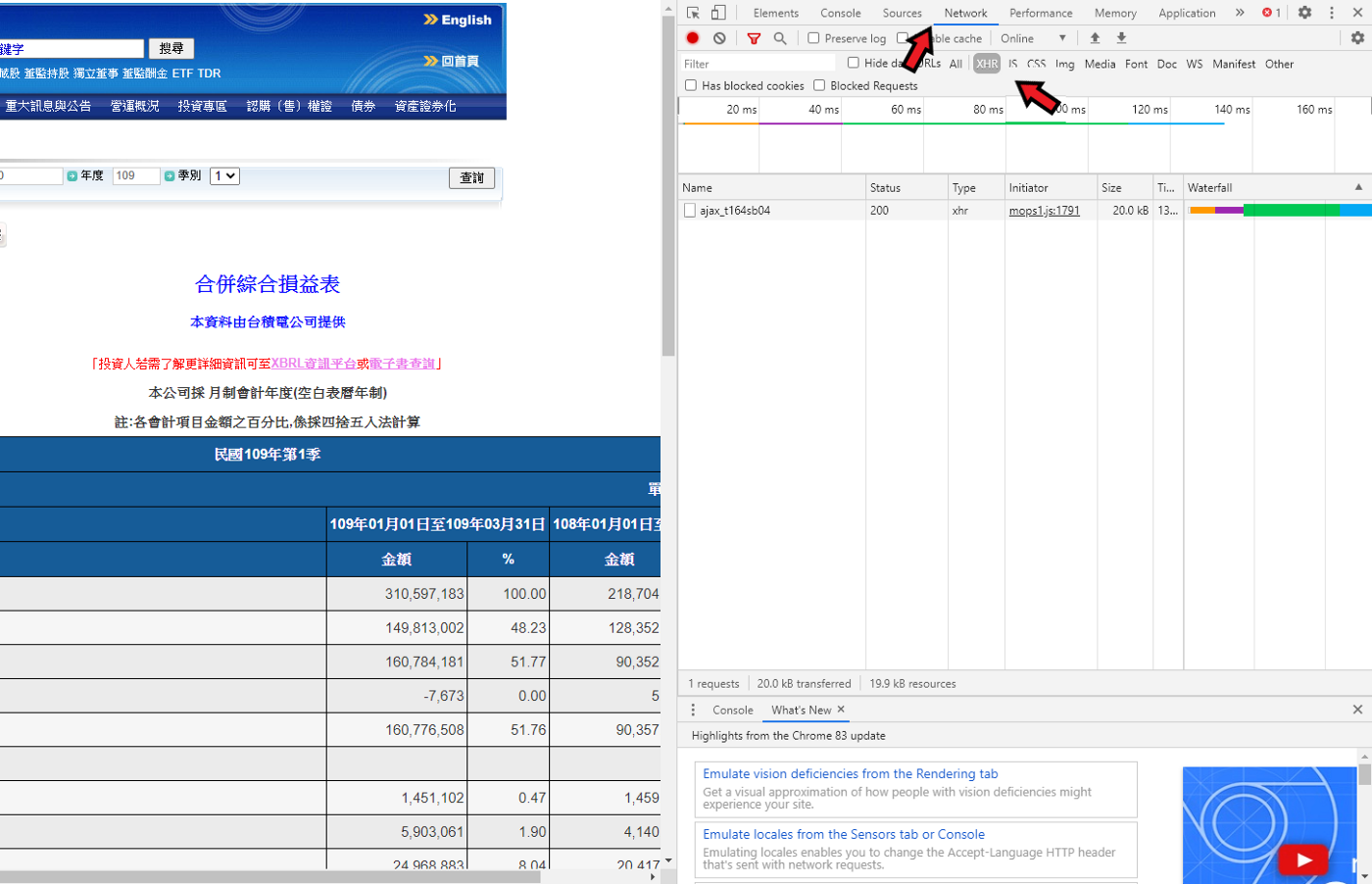
接著選取Network的區塊,再選XHR的區塊,可以看下圖的兩個紅色箭頭,Chrome瀏覽器的這項檢查功能可以幫助解析在瀏覽網頁時發生了甚麼事。
此時在下方物件欄應該會出現一個ajax_t164sb04的物件(如果沒有的話,請再按一次網頁中查詢的按鈕)
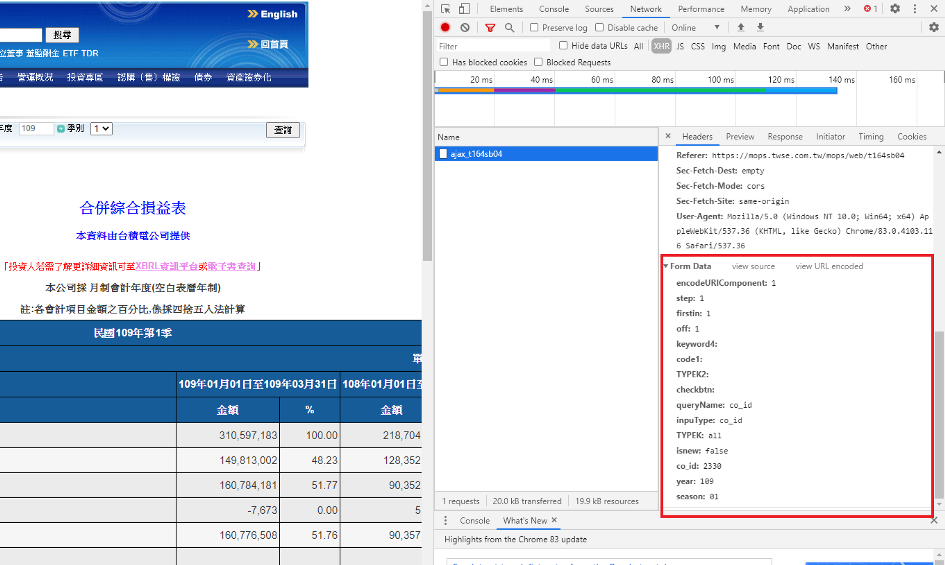
當點下該物件後,旁邊會跳出個小視窗,如同下圖,會看到Request Method的地方寫著post,這邊代表著我們送出的請求類型,常用的有post和get兩種,我們每次在網頁上按個鈕,也就是和網頁互動,就像是在送出請求的動作,而ajax_t164sb04就是我們按查詢後送出請求得到的回應

接著可以在同個區塊把畫面往下拉,如同下圖,會看到最下面Form Data區塊,有許多資訊,這邊就是我們按查詢鈕所送出請求的條件,直觀點可以看到co_id,year,season,分別寫著2330, 109, 01, 這不就是我們上面在查詢前輸入的股票代號、年度和季度資訊嗎!
當綜觀瞭解了網頁請求和資料後,接著就來動手寫code把它爬下來吧!
3.動手寫程式
首先先引入套件
import requests
import pandas as pd
這次和爬取股價的文章不同,不會使用到BeautifulSoup。而這次的requests類型要使用post,我們先將在Request Method那張圖中的Request URL給複製下來,並存成url變數。
url = 'https://mops.twse.com.tw/mops/web/ajax_t164sb04'
接著再把Form Data裏頭的資料複製後,存成字典,空白的部分可以刪除,而其餘資料皆加上引號改成str
payload = {
'encodeURIComponent': '1',
'step': '1',
'firstin': '1',
'off': '1',
'queryName': 'co_id',
'inpuType': 'co_id',
'TYPEK': 'all',
'isnew': 'false',
'co_id': '2330',
'year': '109',
'season': '01',
}
最後利用python來送出請求爬取資料,這時的request是搭配post,後面的data則是我們給予請求的條件,最後再用pd.read_html讀取資料
res = requests.post(url, data = payload)
pd.read_html(res.text)[1]
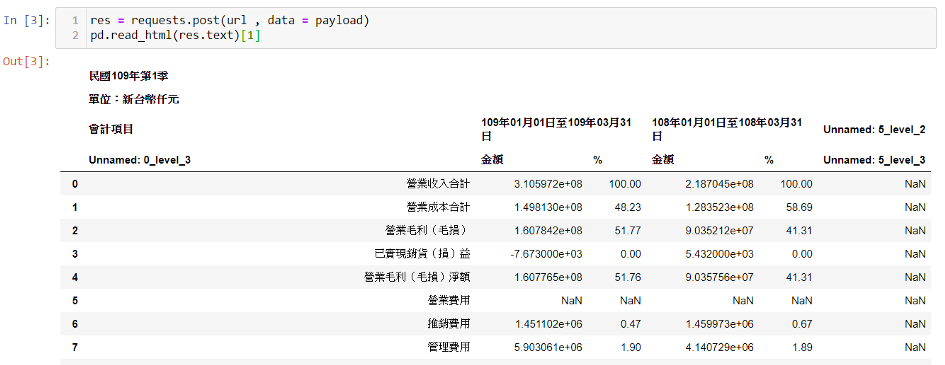
結果會如上圖顯示的,成功抓下來囉! 當成功抓出一個後,就能將資料封裝成函數,然後利用迴圈大量抓取
完整爬蟲程式碼
好比我們把整個爬取的流程寫成叫做get_income_statement()的函式
def get_income_statement(sym, year, season):
url = 'https://mops.twse.com.tw/mops/web/ajax_t164sb04'
payload = {
'encodeURIComponent': '1',
'step': '1',
'firstin': '1',
'off': '1',
'queryName': 'co_id',
'inpuType': 'co_id',
'TYPEK': 'all',
'isnew': 'false',
'co_id': str(sym),
'year': str(year),
'season': str(season),
}
res = requests.post(url , data = payload)
df = pd.read_html(res.text)[1]
return df
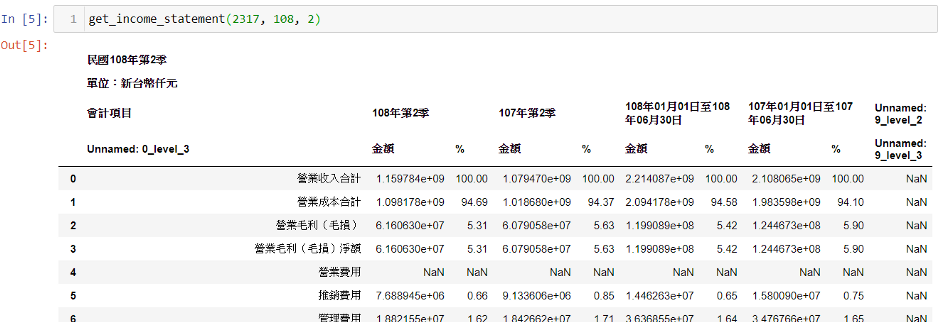
假如今天我們要抓鴻海在108年第2季的損益表,就可以…
get_income_statement(2317, 108, 2)
一樣可以適用哦!
當有了這樣方便的函式簡化爬蟲過程後,不論是要抓取同個股票不同季度、不同年份,或是不同股票但同樣年份和季度,都能輕鬆達成!